Introduction to data analysis at scale – Working with Data and Analytics
Data analysis is often done at scale to analyze large sets of data using the capabilities of cloud computing services such as AWS. Designing a workflow for the data analysis to follow is the pivotal starting point for this to be performed. This will follow five main categories: collection, storage, processing, visualization, and data security.
In this section, we will be introducing you to data analysis on AWS, discussing which services we can use as part of AWS to perform the data analytics workloads we need it to, and walking through the best practices that are part of this. We will understand how to design and incorporate workflows into the IoT network that we currently have and work with it to better power our capabilities.
Data analysis on AWS
Data analysis on AWS can be summarized in five main steps. These steps can be seen in the following diagram:
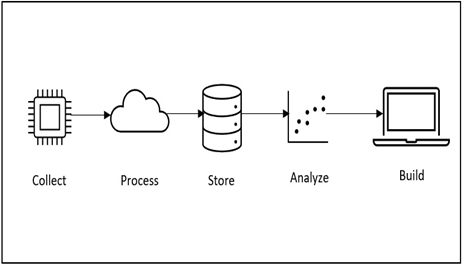
Figure 10.1 – Data analysis workflow on AWS
Let’s look at the steps in more detail:
Collect: In this phase, data is collected from the devices within the environment. Services that are usually in charge of this include AWS IoT Core and AWS IoT Greengrass, which collects the data and ingests it into the cloud.
Process: Data can then be processed according to how the configuration is set up for it. Services such as AWS IoT Analytics are made for this purpose.
Store: Data can then be stored, either temporarily or for long-term storage. This can be done on services such as Amazon Simple Storage Service (S3), Amazon Redshift, and Amazon DocumentDB.
Analyze: Data will then be analyzed. Services such as AWS Glue and Amazon Elastic MapReduce (EMR) can be used for this purpose, while also potentially performing more complex analytics and ML tasks as necessary.
Build: We can then build datasets using this data, making patterns from the processed data that we have received from the workloads that are run.
With that, we have understood the different steps of how a typical data analysis workflow would go at a high level. Now, we can look at the different services in AWS that help facilitate this.
AWS services
Several important services can be used for data processing workloads. These five services are just a few of them, and there are definitely more that can be mentioned and that we encourage you to have a look at. For more information on this, you can refer to the documentation that is linked in the Further reading section at the end of the chapter.
Leave a Reply