Application layer attacks – Examining Security and Privacy in IoT
Application layer attacks target the software and services that run on IoT devices or the cloud services that manage them. Attackers could exploit vulnerabilities in the software or firmware running on the device to gain control over it or access sensitive data. Attackers could also launch attacks such as SQL injection or cross-site scripting (XSS) attacks on the web applications used to manage the devices.
IoT networks face a wide range of attacks, and each layer of the network presents different vulnerabilities. IoT security must be implemented at each layer of the network to mitigate the risks associated with these attacks. The use of encryption, authentication, and access controls can help to secure physical devices and the data transmitted between them. Regular updates and patches should be applied to the software and firmware running on the devices to address any known vulnerabilities. Overall, a layered security approach that considers the entire IoT ecosystem can provide a more robust defense against attacks.
We can see different forms of attacks on embedded IoT systems in Figure 11.2:
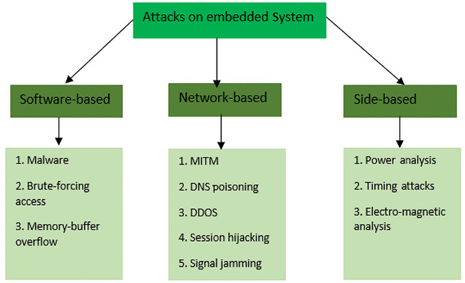
Figure 11.2 – Different attacks on embedded systems
The diagram provides a structured view of potential vulnerabilities an embedded system may face, categorizing them based on the method or perspective of the attack. It categorizes the different attacks into three main types: Software-based, Network-based, and Side-based, described as follows:
Software-based attacks:
- Malware: Malicious software intended to damage or exploit an embedded system
- Brute-forcing access: A method of trial and error whereby an attacker attempts to guess the correct access credentials
- Memory-buffer overflow: A situation where a program writes data outside the bounds of pre-allocated fixed-length buffers, leading to potential code execution or system crashes
Network-based attacks:
- MITM: An attack where the attacker secretly relays and possibly alters the communication between two parties who believe they are communicating directly with each other
- Domain Name System (DNS) poisoning: An attack where the attacker redirects DNS entries to a malicious site
- DDOS: An attempt to disrupt the regular functioning of a network by flooding it with excessive traffic
- Session hijacking: When an attacker takes over a user’s session to gain unauthorized access to a system
- Signal jamming: An interference with the signal frequencies that an embedded system might use, rendering it inoperable or reducing its efficiency
Side-based attacks:
- Power analysis: Observing the power consumption of a device to extract information
- Timing attacks: Analyzing the time taken to execute cryptographic algorithms to find vulnerabilities
- Electromagnetic analysis: Using the electromagnetic emissions of a device to infer data or operations
With that understanding, we can now look at how cloud providers such as Amazon Web Services (AWS) provide powerful tools to manage security on the platform.